The Cool Mammals Project
This is a prototype project with the objective of summarizing, in a small space, the integrated use of diverse Machine Learning (ML) and Data Science (DS) methods. Good DS is usually seen as preceding good ML, which in its turn would be the end-point of anything we might need. However, this relationship could be more fruitful (in both practical and theoretical terms) if understood, instead, as an active cycle, with ML models also informing the construction and the interpretation of meaningful datasets. I try to illustrate what I mean with that with this cool mammals project.
A first catalyst of this enterprise is my amazement with the abundance of high-quality, freely-available data, algorithms and documentation out there, which empower us to put so many ideas into practice! In nearly every DS or ML piece of expertise, from data gathering, manipulation and visualization to image and language processing, the cutting-edge technologies are made promptly accessible to anyone with interest in them.
In the spirit of contributing to this evergrowing, beautiful culture, and as a deliberate effort of self organization, I aim to describe the evolution of the project and to catalog it in the currently proper mediums: data gathering and code writting (stored on GitHub), deploying models for inference and informative visualization (as a web application) and the documentation of each project part in an instructional format (blog posts).
In a nutshell, this project will cover:
- Object detection: Train a model to detect pre-defined mammal species in images and use it for inference in new images;
- Data Mining: Unsupervised algorithm to form a corpus-based knowledge representation, Named Entity Recognition for identification of countries names and data visualization with clean and informative graphics;
- Web application: Organizes and deploys all functionalities in an end-user web application.
Important: This project serves as a proof of concept for the idea of integrating recurrently ML and DS methods in a single application, and hopefully it will motivate independent pratictioners to implement their own ideas. The resources in it should not be used commercially, but only for educational purposes.
1. Object Detection
I start describing how to make use of advanced image processing models for a personal project. The chosen library is the Tensorflow Object Detection API, from which I repurpose a pre-trained SSD Inception model to identify specific mammal species (a technique known as transfer learning).
For each mammal species I collected 100 photos for training and 10 for testing. The model trained on this limited dataset yields good results most of the times, but the number of examples proved to be too small for finer detection, specially for classes that look very similar, such as wolf and fox.
List of mammal species: bat, capybara, elephant, fox, giraffe, hedgehog, hippo, kangaroo, koala, lion, panda, rhino, sloth, tiger, wolf, zebra.
2. Data Mining
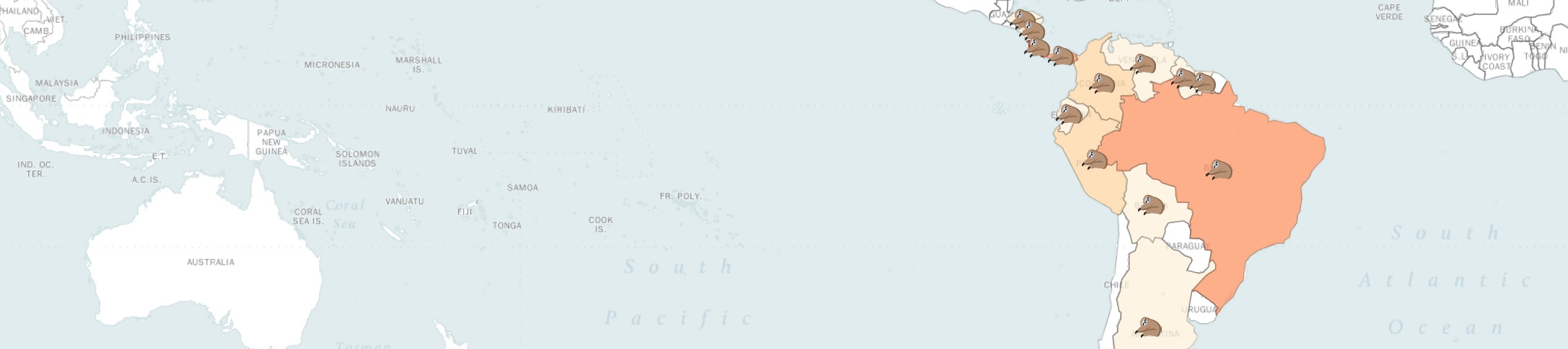
Once the model identified which mammals are present in the photo, how can I bring up extra useful information to the user of my system? I propose a solution that is unsupervised and scalable: I collect the text in a large number of web pages related to a specific mammal and estimate the countries where it is most likely to be found by counting the frequency of occurrence of countries names in those pages. To fetch the texts I use Scrapy and to identify countries names I use SpaCy.
I present the resulting dataset in visually engaging and informative ways. I use Plotly to generate a clean bar plot with the frequencies of occurrence for each country and Folium to create a choropleth map with the cute mammal icons.
A valuable concept touched in this section is the Corpus-Based Knowledge Representation. By implementing an example, it is possible to observe at first-hand some advantages and disavantages of this idea. I discuss the biases and limitations of my particular implementation.
3. Web application
Finally, I demonstrate how to pack all those methods an a single web application built in Django. I show how it can be served locally and made available to external users with Ngrok.